What Every Programmer Should Know Computer 002
上一篇我们介绍了早期计算机和现代计算机构成位的不同硬件,计算机最底层的抽象“从硬件层抽象出二进制值”,以及二进制值的简单计算(和对应的门电路)。这一篇文章,将介绍一些更复杂的门电路(Gate Combinations )。
复杂门电路的重要设计思想:Design small circuits to be used in a bigger circuit。
上一篇我们介绍了早期计算机和现代计算机构成位的不同硬件,计算机最底层的抽象“从硬件层抽象出二进制值”,以及二进制值的简单计算(和对应的门电路)。这一篇文章,将介绍一些更复杂的门电路(Gate Combinations )。
复杂门电路的重要设计思想:Design small circuits to be used in a bigger circuit。
本文的目的是快速了解计算机系统。文章标题模仿了《What Every Programmer Should Know About Memory》
本篇是论文的中文简单翻译
分布式有状态的流处理允许在云上部署和执行大规模的流数据计算,并且要求低延迟和高吞吐。这种模式一个比较大的挑战,就是其容错能力,能够应对潜在的 failure。现有的方案都是依赖周期性地全局状态的快照做失败恢复。 这些方法有两个主要的缺点:
本篇论文中提出了一个适用于现代数据流执行引擎,并最大限度减少空间需求的轻量级算法 Asynchronous Barrier Snapshot(ABS)。ABS在无环的拓扑结构中只对有状态的operator进行快照,对于有环的执行拓扑只保存最小化的record日志。在Apache Flink(一个支持有状态的分布式流处理分析引擎)中实现了ABS。通过评估表明,这种算法对程序执行没有很重的影响,并且保持了线性的可扩展性,在频繁的快照情况下也表现良好。
关键词: 容错,分布式计算,流处理,数据流,云计算,状态管理
通常在mysql中存储树形结构的方案,是通过在子节点上存储父节点编号的方案来实现的。这种方案可以很直观的体现各个节点之间的关系,通常可以满足大多数需求。
但是当数据量变大和层级关系变深后,对于部分需求(例如,判断节点是否其他节点的子节点)这样的存储方式很难满足要求。这类需求实质上需要在内存中构建一棵树,通过遍历树来给出答案。如果还是使用parent_id这种存储模型,显然需要按照树的层级关系递归向下搜索。
例如,以mysql数据库样例Employees表为例。
1 | +----------------+ |
employees表有reportsTo字段引用employeeNumber字段。描述employee之间的层级关系。
上述的存储方式,获取树的流程为:
1 | List<Employee> employees; |
上述操作是递归方式查询,查询效率仍会随着树层级深度的提高而变差。
本篇是论文的中文简单翻译
Presto是一个开源分布式查询引擎,支撑了Facebook内部大部分的SQL分析工作。Presto的设计目标是具有适应性、灵活性和可扩展性。它支持具有不同特征的各种各样的用例。这些用例的范围从要求亚秒级延迟的面向用户的报表应用到花费数小时的聚合或关联数TB数据的ETL任务。Presto的连接器API允许以插件的方式为数十个数据源提供高性能I/O接口,包括Hadoop数据仓库、RDBMS数据库、NoSQL系统和流处理系统。在本论文中,我们概述了Presto在Facebook内部支撑的一系列用例。然后,我们描述了它的架构和实现,并阐述了使其能够支持这些用例的功能和性能优化。最后,我们展示了性能结果,从而论证了我们主要的设计决策的影响。
关键词: SQL,查询引擎,大数据,数据仓库
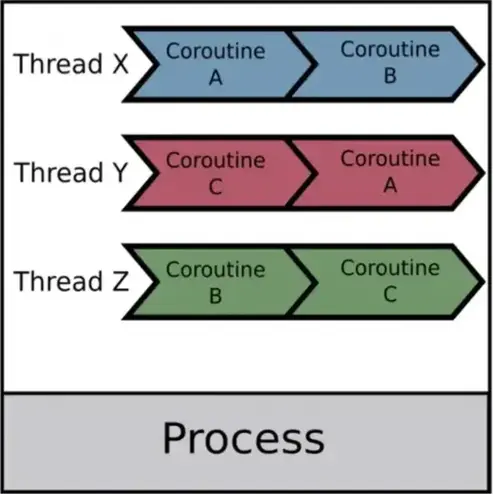
本文会介绍操作系统中的进程,线程和协程。
diff算法用于比较文本间的差异,通常用于版本控制系统,例如 git( $git diff)。
diff算法的目的是计算出文本间的差异,那么首先介绍下什么是文本差异。文本差异就是目标文本和源文本之间的区别,也就是将源文本变成目标文本所需要的操作。这里的操作包括插入(insert)和 删除(delete)。
假设我们要计算下面两个字符串之间的差异:
ABCABBACBABAC一种可能的结果是删除a中的全部字符,然后再插入b中的全部字符。
1 | - A |
上面的差异是有效的,但是并不是较好的差异。差异中的更改数量应该尽可能少。例如:
1 | 1. - A 2. - A 3. + C |
上面的3种差异都是拥有最小更改数量的方案。但是第二种和第三种没有第一种看起来“直观”。“直观”有两个特点。
1 | Good: - one Bad: - one |
1 | Good: class Foo Bad: class Foo |
本篇是论文的中文简单翻译
应⽤程序使⽤多个异构数据库是⼀种常⻅的模式,其中每个数据库都⽤于满⾜特定需求,例如存储规范形式的数据或提供⾼级搜索功能。因此,对于应⽤程序来说,需要保持多个数据库同步。我们观察到了⼀系列试图解决这个问题的不同模式,例如双写和分布式事务。然⽽,这些⽅法在可行性、稳健性和维护⽅⾯存在局限性。最近出现的另⼀种⽅法是利⽤变更数据捕获 (CDC) 从数据库的事务⽇志中捕获更改的行,并最终以低延迟将它们传递到下游。为了解决数据同步问题,还需要复制数据库的完整状态,⽽事务⽇志通常不包含完整的更改历史记录。同时,有些⽤例需要事务⽇志事件的⾼可⽤性,以便数据库尽可能保持同步。
为了应对上述挑战,我们开发了⼀种新颖的 CDC数据库框架,即 DBLog。 DBLog 利⽤基于⽔印的⽅法,允许我们将事务⽇志事件与我们直接从表中选择的行交错以捕获完整状态。我们的解决⽅案允许⽇志事件继续进行,⽽不会在处理选择时停⽌。可以随时在所有表、特定表或表的特定主键上触发选择。 DBLog 以块的形式执行选择并跟踪进度,允许它们暂停和恢复。⽔印⽅法不使⽤锁,对源的影响最⼩。 DBLog⽬前被 Netflix 的数⼗个微服务⽤于⽣产。
关键字:
本文是 Doug Lea 的 “Scalable IO in Java” 读书笔记
在一般的网络或分布式服务等应用程序中,大都具备一些相同的处理流程,例如:
当然在实际应用中每一步的运行效率都是不同的,例如其中可能涉及到xml解析、文件传输、web页面的加载、计算服务等不同功能。