Cpu-Cache和伪共享
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
下面的代码引用自http://coderplay.iteye.com/blog/1485760
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class L1CacheMiss {
private static final int RUNS = 10;
private static final int DIMENSION_1 = 1024 * 1024;
private static final int DIMENSION_2 = 62;
private static long[][] longs;
public static void main(String[] args) throws Exception {
longs = new long[DIMENSION_1][];
for (int i = 0; i < DIMENSION_1; i++) {
longs[i] = new long[DIMENSION_2];
}
System.out.println("starting....");
final long start = System.nanoTime();
long sum = 0L;
for (int r = 0; r < RUNS; r++) {
for (int j = 0; j < DIMENSION_2; j++) {
for (int i = 0; i < DIMENSION_1; i++) {
sum += longs[i][j];
}
}
}
System.out.println("duration = " + (System.nanoTime() - start));
}
}
|
这里定义了一个二维数组,第一维长度是1024*1024,第二维长度是62,这里遍历二维数组。由于二维数组中每一个数组对象的长度是62,那么可以知道,long类型的数组对象头的大小是16字节(这里默认开启了指针压缩),每个long类型的数据大小是8字节,那么一个long类型的数组大小为16+8*62=512字节。
第一种情况,因为二维数组中的每一个数组对象占用的内存大小是512字节,而缓存行的大小是64字节,那么使用第一种遍历方式,假设当前遍历的数据是longs[i][j],那么下一个遍历的数据是longs[i+1][j],也就是说遍历的不是同一个数组对象,那么这两次遍历的数据肯定不在同一个缓存行内,也就是产生了Cache Miss;
在第二种情况中,假设当前遍历的数据是longs[i][j],那么下一个遍历的数据是longs[i][j+1],遍历的是同一个数组对象,所以当前的数据和下一个要遍历的数据可能都是在同一个缓存行中,这样发生Cache Miss的情况就大大减少了。
伪共享
在Java程序中,数组的成员在缓存中也是连续的. 其实从Java对象的相邻成员变量也会加载到同一缓存行中. 如果多个线程操作不同的成员变量, 但是相同的缓存行, 伪共享(False Sharing)问题就发生了.
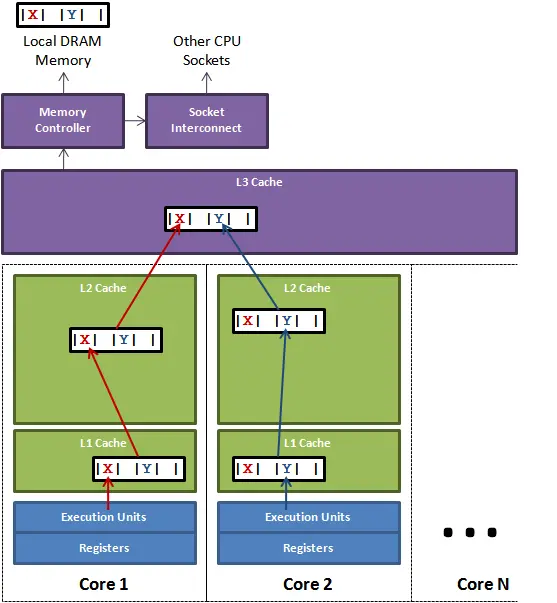
![FalseSharing]()
在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去 竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要 使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
表面上X和Y都是被独立线程操作的, 而且两操作之间也没有任何关系.只不过它们共享了一个缓存行, 但所有竞争冲突都是来源于共享。
如何避免伪共享
假设有一个类中,只有一个long类型的变量:
1
2
3
| public final static class VolatileLong {
public volatile long value = 0L;
}
|
这时定义一个VolatileLong类型的数组,然后让多个线程同时并发访问这个数组,这时可以想到,在多个线程同时处理数据时,数组中的多个VolatileLong对象可能存在同一个缓存行中,通过上文可知,这种情况就是伪共享。
怎么样避免呢?在Java 7之前,可以在属性的前后进行padding,例如:
1
2
3
4
| public final static class VolatileLong {
long p1, p2, p3, p4, p5, p6;
public volatile long value = 0;
}
|
一条缓存行有64字节, 而Java程序的对象头固定占8字节(32位系统)或12字节(64位系统默认开启压缩, 不开压缩为16字节)。我们只需要填6个无用的长整型补上6*8=48字节, 让不同的VolatileLong对象处于不同的缓存行, 就可以避免伪共享了(64位系统超过缓存行的64字节也无所谓,只要保证不同线程不要操作同一缓存行就可以). 这个办法叫做补齐(Padding).
这里有一个问题:在马丁的博客有提到中Java7优化了无用字段,会使这种形式的补位无效,需要采用暴露补位属性的方法来避免优化,但在我的测试里,这种形式是有效的。
而在Java 8中,提供了@sun.misc.Contended注解来避免伪共享,原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。
注意,执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。
下面看下测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import java.util.concurrent.atomic.AtomicLong;
public class FalseSharing implements Runnable {
public final static int NUM_THREADS = 4;
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong1[] longs = new VolatileLong1[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong1();
}
}
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].set(i);
}
}
public final static class VolatileLong1 extends AtomicLong{
}
public static class VolatileLong2 extends AtomicLong
{
long p1, p2, p3, p4, p5, p6, p7 = 7L;
}
@sun.misc.Contended
public final static class VolatileLong3 extends AtomicLong{
}
}
|
@sun.misc.Contended注解
上文中将@sun.misc.Contended注解用在了对象上,@sun.misc.Contended注解还可以指定某个字段,并且可以为字段进行分组,下面通过代码来看下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public class ContendedTest {
byte a;
@sun.misc.Contended("first")
long b;
@sun.misc.Contended("first")
long c;
int d;
private static Unsafe UNSAFE;
static {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
UNSAFE = (Unsafe) f.get(null);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws NoSuchFieldException {
System.out.println("offset-a: " + UNSAFE.objectFieldOffset(ContendedTest.class.getDeclaredField("a")));
System.out.println("offset-b: " + UNSAFE.objectFieldOffset(ContendedTest.class.getDeclaredField("b")));
System.out.println("offset-c: " + UNSAFE.objectFieldOffset(ContendedTest.class.getDeclaredField("c")));
System.out.println("offset-d: " + UNSAFE.objectFieldOffset(ContendedTest.class.getDeclaredField("d")));
ContendedTest contendedTest = new ContendedTest();
System.out.println("Shallow Size: " + MemoryUtil.memoryUsageOf(contendedTest) + " bytes");
System.out.println("Retained Size: " + MemoryUtil.deepMemoryUsageOf(contendedTest) + " bytes");
}
}
|
这里在变量b和c中使用了@sun.misc.Contended注解,并将这两个变量分为1组,执行结果如下:
1
2
3
4
5
6
| offset-a: 16
offset-b: 152
offset-c: 160
offset-d: 12
Shallow Size: 296 bytes
Retained Size: 296 bytes
|
可见int类型的变量的偏移地址是12,也就是在对象头后面,因为它正好是4个字节,然后是变量a。@sun.misc.Contended注解的变量会加到对象的最后面,这里就是b和c了,那么b的偏移地址是152,之前说过@sun.misc.Contended注解会在变量前后各加128字节,而byte类型的变量a分配完内存后这时起始地址应该是从17开始,因为byte类型占1字节,那么应该补齐到24,所以b的起始地址是24+128=152,而c的前面并不用加128字节,因为b和c被分为了同一组。
我们算一下c分配完内存后,这时的地址应该到了168,然后再加128字节,最后大小就是296。内存结构如下:
| d:12~16 | — | a:16~17 | — | 17~24 | — | 24~152 | — | b:152~160 | — | c:160~168 | — | 168~296 |
如果b,c 不分为一组,那么b和c中增加了128字节的padding。
| d:12~16 | — | a:16~17 | — | 17~24 | — | 24~152 | — | b:152~160 | — | 160~288 | — | c:288~296 | — | 296~424 |