JavaCC 简介
JavaCC 是 java 生态中常用的Parser Generator。特征如下:
- JavaCC 生成的解析器是基于LL 的,默认是LL(1),通过配置可以支持 LL(K)。
- 由于是LL 方式,需要用户自己书写递归下降的语法规则来避免出现左递归问题。
- JavaCC 支持 EBNF 语法范式。
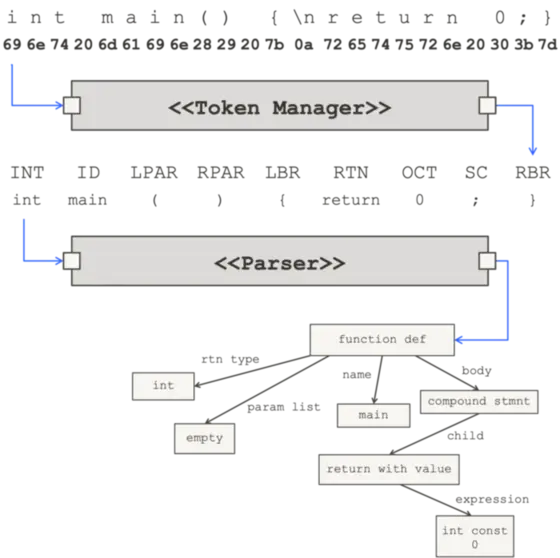
JavaCC的工作流程如下:
- 令牌管理器读入一个字符序列并生成一个称为令牌的对象序列。用于将字符序列分解为标记序列的规则取决于语言-它们由用户作为正则表达式的集合提供。
- 解析器使用一个令牌序列,分析它的结构,并产生一个由用户定义的输出。
JavaCC 语法
JavaCC 的文件结构如下:
1 | javacc_input ::= javacc_options |
- javacc_options 是选项列表
- 在PARSER_BEGIN和PARSER_END后面的名称必须相同,内容是生成的Parser 的名字。
- 在PARSER_BEGIN和PARSER_END结构之间是一个常规的Java编译单元(Java术语中的编译单元是Java文件的全部内容)。这可以是任何Java编译单元,只要它包含一个类声明,其名称与生成的解析器的名称相同。
- 在PARSER_END后面是语法产生式列表。
语法描述-产生式
语法文件的核心是production 列表,产生式的结构如下:
1 | production ::= javacode_production |
- javacode_production 和 bnf_production 用于定义生成语法分析器的语法。
- regular_expr_production 用于描述语法中的 Token。Token Manager 就是基于此生成。
- token_manager_decls 用于引入插入到生成的令牌管理器中的声明。
javacode
1 | javacode_production ::= "JAVACODE" |
javacode_production 是一种为某些生产编写Java代码的方法,而不是通常的EBNF扩展。当需要识别与上下文无关的内容或出于某种原因很难为其编写语法时很有用。
下面是使用JAVACODE的示例。在这个例子中,非终结符skip_to_matching_brace消耗输入流中的令牌,直到匹配的右括号(假设左括号刚刚被扫描):
1 | JAVACODE |
- getToken 方法让你能够访问令牌流中的令牌,其参数是一个整数,表示从当前下一个要读取的令牌开始的偏移量。例如:
- getToken(0) 返回当前Token
- getToken(1) 返回下一个令牌,依此类推。
- token 变量:这是一个可以直接使用的 Token 类型的变量,它指向最后一个被解析器消耗(consumed)的令牌。这在动作中获取当前已匹配的令牌时非常方便。
- getNextToken() 方法:这个方法属于 Token Manager(令牌管理器) 的接口。调用它会消耗当前令牌并返回下一个令牌。通常,在仅使用令牌管理器进行词法分析(例如,在不涉及语法解析的情况下单独扫描令牌)时会用到它;
使用javacode_production时必须小心,JavaCC 只是将其视为黑盒。当JAVACODE生产出现在选择点时,JavaCC无法根据javacode_production选择分支,此时必须在javacode_production前面引入其他产生式。例如:
1 | (* 无法判断走哪个分支 *) |
正则表达式
1 | (* 正则产生式 *) |
正则表达式产生式用于定义由令牌管理器(自动生成的)处理的词法实体。正则表达式的产生从它所应用的词法状态的规范(词法状态列表)开始。有一个标准的词法状态叫做DEFAULT。如果省略了词法状态列表,则正则表达式产生式应用于词法状态DEFAULT。词法状态列表描述了相应的正则表达式产生式所应用的词法状态集。如果将其写成<*>,则正则表达式产生式适用于所有词法状态。否则,它适用于角括号内标识符列表中的所有词汇状态。
词法状态(Lexical States)允许你在不同上下文中对同一字符序列进行不同的词法分析。词法状态就像词法分析器的"模式",在不同的模式下,相同的输入字符可能被解释为不同的词法单元。例如:
状态 描述 示例 DEFAULT 默认状态 正常解析代码 IN_COMMENT 注释状态 在 /* … */ 中忽略内容 IN_STRING 字符串状态 在 “…” 中处理转义字符 IN_CHAR 字符状态 在 ‘…’ 中处理字符
然后是regexpr_kind,用于描述是哪一种正则表达式生成。共有如下 4 种:
| 类型 | 描述 |
|---|---|
| TOKEN | 这个正则表达式产生式中的正则表达式描述语法中的标记。令牌管理器为这样的正则表达式的每个匹配创建一个Token对象,并将其返回给解析器。 |
| SPECIAL_TOKEN | 这个正则表达式产生式中的正则表达式描述了特殊的标记。特殊标记类似于标记,除了它们在解析过程中没有意义-也就是说BNF生产忽略它们。但是,特殊的标记仍然会传递给解析器,以便解析器操作可以访问它们。通过使用specialToken类中的字段Token将特殊标记链接到相邻的真实的标记,将特殊标记传递给解析器。特殊标记在处理词汇实体(如注释)时很有用,注释对解析没有意义,但仍然是输入文件的重要组成部分。 |
| SKIP | 在这个正则表达式生成中,与正则表达式的匹配被令牌管理器简单地跳过(忽略)。 |
| MORE | 有时候,逐步构建一个要传递给解析器的标记是很有用的。这种正则表达式的匹配项存储在缓冲区中,直到下一个TOKEN或SPECIAL_TOKEN匹配。然后,缓冲区中的所有匹配和最后的TOKEN/SPECIAL_TOKEN匹配被连接在一起,形成一个传递给解析器的TOKEN/SPECIAL_TOKEN。如果一个匹配到SKIP正则表达式的匹配跟在一个MORE匹配的序列之后,那么缓冲区的内容将被丢弃。 |
最后是正则表达式规范,正则表达式定义开始了对词汇实体的实际描述,这些实体是正则表达式生成的一部分。每个正则表达式产生式可以包含任意数量的正则表达式规范。每个正则表达式规范都包含一个正则表达式,后跟一个可选的Java块(词法操作)。这之后是一个词汇状态的标识符(也是可选的)。
- 只要这个正则表达式被匹配,就会执行词法操作(如果有的话)
- 然后执行任何公共标记操作。
- 然后,采取取决于正则表达式生成类型的动作。
- 最后,如果指定了一个词法状态,令牌管理器将移动到该词法状态以进行进一步处理(令牌管理器最初在状态DEFAULT中启动)。
正则表达式
1 | (* 正则表达式 *) |
语法文件中有两个地方可以写入正则表达式:
- 在正则表达式规范(正则表达式生成的一部分)中,
- 作为一个扩展中的扩展单位。当以这种方式使用正则表达式时,就好像正则表达式在此位置以以下方式规范,然后由其标签从扩展单元引用:
1 | <DEFAULT> TOKEN : |
- 第一种正则表达式是字符串文字。如果Token管理器处于此正则表达式适用的词法状态,并且输入流中的下一组字符与此字符串文字相同(可能忽略大小写),则正在分析的输入与此正则表达式匹配。
- 正则表达式也可以是更复杂的正则表达式,使用它可以定义更多涉及的正则表达式(比字符串字面量)。这样的正则表达式被放置在尖括号<…>中,并且可以可选地用标识符来标记。此标签可用于从扩展单元或其他正则表达式中引用此正则表达式。如果标签前面有一个#,那么这个正则表达式不能从扩展单元引用,而只能从其他正则表达式中引用。当#存在时,正则表达式被称为私有正则表达式。
- 正则表达式可以是对其他带标签的正则表达式的引用,在这种情况下,它被写为括在尖括号<…>中的标签。
- 最后,正则表达式可以是对预定义的正则表达式
<EOF>的引用,其在文件的结尾处匹配。
Token管理器不将私有正则表达式作为令牌进行匹配。它们的目的仅仅是为了方便定义其他更复杂的正则表达式。
考虑以下定义Java浮点字面值的示例:
1 | TOKEN : { |
在该示例中,使用另一令牌的定义(即,FLOATING_POINT_LITERAL)来定义令牌EXPONENT。标签#之前的EXPONENT表示它的存在仅仅是为了定义其他令牌(在本例中为FLOATING_POINT_LITERAL)。FLOATING_POINT_LITERAL的定义不受#的存在或不存在的影响。如果省略#,令牌管理器将错误地将像E123这样的字符串识别为类型为EXPONENT的法律的令牌(而不是Java语法中的IDENTIFIER)。
复杂正则表达式
1 | complex_regular_expression_choices ::= complex_regular_expression ( "|" complex_regular_expression )* |
- 一个复杂的正则表达式单元可以是一个字符串字面量,在这种情况下,这个单元只有一个匹配项,即字符串字面量本身。
- 复杂正则表达式单元可以是对另一个正则表达式的引用。另一个正则表达式必须被标记,以便可以引用它。这个单元的匹配项是这个其他正则表达式的所有匹配项。正则表达式中的这种引用不能在标记之间的依赖关系中引入循环。
- 复杂正则表达式单元可以是字符列表。字符列表是定义一组字符的一种方式。这种复杂正则表达式单元的匹配是字符列表允许的任何字符。
- 复杂正则表达式单元可以是一组带括号的复杂正则表达式选项。带括号的选项集可以(可选)添加以下后缀:
|后缀|描述|
|+|带括号的选择集的法律的匹配的一个或多个重复|
|*|带括号的选择集的法律的匹配的零次或多次重复|
|?|是空字符串或嵌套选择的匹配。|
与BNF展开式不同,正则表达式
[...]不等同于正则表达式(...)?。这是因为[...]结构用于描述正则表达式中的字符列表。
字符列表描述一组字符。字符列表的法律的匹配是此集合中的任何字符。字符列表是由方括号内的逗号分隔的字符描述符的列表。每个字符描述符描述单个字符或一系列字符,并且将其添加到字符列表的字符集中。如果字符列表以~符号为前缀,则它表示的字符集是不在指定集合中的任何UNICODE字符。
字符描述符可以是单个字符串字面量,在这种情况下,它描述了包含该字符的单例集;或者它是两个由-分隔的单个字符串字面量,在这种情况下,它描述了这两个字符之间的所有字符的集合。
token_manager_decls
1 | token_manager_decls ::= "TOKEN_MGR_DECLS" ":" ClassOrInterfaceBody |
令牌管理器声明以保留字TOKEN_MGR_DECLS开始,后面是:,然后是一组Java声明和语句(可能在类或接口的主体中)。这些声明和语句被写入生成的令牌管理器中,并且可以从词法操作中访问。在JavaCC语法文件中只能有一个令牌管理器声明。
bnf
1 | (* BNF 产生式 *) |
BNF产生式是 JavaCC 语法中的标准产生式。每个 BNF 产生式的左侧都是一个非终结符定义,然后,BNF产生式根据右边的BNF展开来定义这个非终结符。每个非终结符都被转换为生成的解析器中的一个方法,非终结符的名称就是方法的名称,声明的参数和返回值是在解析树中上下传递值的方法。在产生式右侧的非终结符被写为方法调用,因此在树中向上和向下传递值是使用与方法调用和返回完全相同的范式来完成的。
BNF productions的默认访问修饰符是public。
在BNF产生式的右侧有两个部分。第一部分是一组任意的Java声明和代码(Java块)。此代码在为Java非终结符生成的方法的开头生成。因此,每次在解析过程中使用这个非终结符时,都会执行这些声明和代码。这一部分的声明对BNF扩展中的所有Java代码都是可见的。JavaCC不对这些声明和代码进行任何处理,只是跳到匹配的结束括号,收集在此过程中遇到的所有文本。因此,Java编译器可以检测到JavaCC处理的代码中的错误。
第二部分是 BNF 扩展。一个扩展被写为一个扩展单元序列,扩展单元通过串联描述了文法解析规则。
- 扩展单元可以是local_lookahead规范,指示生成的解析器如何在选择点做出选择。
- 扩展单元可以是一组Java声明和括在大括号内的代码(Java块)。这些操作也称为解析器操作。这是在解析非终结符的方法中在适当的位置生成的。只要解析过程成功地越过该点,就会执行该块。当JavaCC处理Java块时,它不执行任何详细的语法或语义检查。在先行评估期间不执行操作。
- 扩展单元可以是一个或多个扩展选项的括号集合。在这种情况下,扩展单元的合法解析是嵌套扩展选项的任何合法解析。带括号的扩展选项集可以(可选)添加以下后缀:
| 后缀 | 描述 |
|---|---|
+ | 带括号的扩展选项集合的一个或多个重复。 |
* | 带括号的扩展选项集合的零次或多次重复。 |
? | 带括号的扩展选项集合的零次或一次重复。另一种语法是将展开选项括在方括号[...]中。 |
- 扩展单元可以是正则表达式。则扩展单元的合法解析是匹配此正则表达式的任何标记。当正则表达式匹配时,它创建一个类型为Token的对象。这个对象可以通过在正则表达式前面加上variable =来将其分配给一个变量来访问。一般来说,您可以在=的左侧拥有任何有效的Java赋值。在先行评估期间不执行此分配。
- 扩展单元可以是非终结符(上面语法中的最后一个选择)。在这种情况下,它采用方法调用的形式,将非终结符名称用作方法名称。成功解析非终结符会导致对方法调用中放置的参数进行操作并返回一个值(如果非终结符未声明为类型void)。返回值可以通过在正则表达式前面加上variable =来分配(可选)给变量。一般来说,您可以在=的左侧拥有任何有效的Java赋值。在先行评估期间不执行此分配。不能以引入左递归的方式在扩展中使用非终结符。JavaCC会为您检查这个。
lookahead
1 | local_lookahead ::= "LOOKAHEAD" "(" [ java_integer_literal ] [ "," ] [ expansion_choices ] [ "," ] [ "{" java_expression "}" ] ")" |
本地lookahead规范用于影响生成的解析器在语法中的各个选择点做出选择的方式。以保留字LOOKAHEAD开始,后跟括号内的一组lookahead约束。有三种不同类型的lookahead约束:
- lookahead限制(整数文字)
- 语法lookahead(扩展选择)
- 语义lookahead(大括号内的表达式)。
必须 至少存在一个lookahead约束 。如果存在多个lookahead约束,则必须用逗号分隔。
| 约束 | 描述 |
|---|---|
| lookahead限制 | 这是可用于选择的lookahead token的最大数量。这将覆盖由LOOKAHEAD选项指定的默认值。此lookahead限制仅适用于local_lookahead位置处的选择点。如果local_lookahead规范不在选择点,则忽略lookahead限制(如果有的话)。 |
| 语法lookahead | 这是一个扩展(或扩展选择),用于确定是否采用该local_lookahead规范所应用的特定选择。如果没有提供,则解析器使用在lookahead确定期间选择的扩展。如果local_lookahead规范不在选择点,则忽略语法lookahead(如果有的话)。 |
| 语义lookahead | 这是一个布尔表达式,在解析过程中,每当解析器越过该点时,都会对其求值。如果表达式的计算结果为true,则分析正常继续。如果表达式的计算结果为false,并且local_lookahead规范位于选择点,则不采用当前选择,并考虑下一个选择。如果表达式的计算结果为false,并且local_lookahead规范不在选择点,则解析将中止并返回解析错误。与在非选择点处被忽略的其他两个lookahead约束不同,语义lookahead总是被评估。事实上,如果在评估其他lookahead语法检查期间遇到lookahead语义检查,则甚至会评估语义lookahead检查。 |
lookahead 默认值:
- 如果未提供lookahead限制,并且如果提供了lookahead语法,则lookahead限制默认为最大整数值(2147483647)。这基本上实现了infinite lookahead -即,根据需要向前查找尽可能多的标记,以匹配已经提供的语法向前查找。
- 如果既没有提供lookahead限制也没有提供语法lookahead(这意味着提供了语义lookahead),则lookahead限制默认为0。这意味着不执行语法lookahead,而只执行语义lookahead。
- 如果未提供语法lookahead,则默认为应用local_lookahead规范的选项。如果local_lookahead规范不在选择点,则语法lookahead将被忽略-因此默认值不相关。
- 如果没有提供语义lookahead,它默认为布尔表达式true。也就是说,它默认地通过。
lookahead 例子
- lookahead数字
1 | void identifier_list() : |
- lookahead语法
1 | void TypeDeclaration() : |
- lookahead语义
1 | void BC() : |
QuickStart
通过下面的 javacc 文件,我们实现了对嵌套括号对计数的能力。
1 | PARSER_BEGIN(BracesCount) |
可以通过下面的代码测试生成的 parser。
1 | public class Tutorial01Test { |
Option static
默认 JavaCC 生成的Parser是静态解析器。静态 Parser:
- 性能更优
- 内存效率高
- 只加载一次语法表、状态机等数据结构
- 减少重复对象的创建
- 适合长时间运行的应用程序
- 缓存友好,静态数据在JVM中更容易被优化和缓存,减少垃圾回收压力。
但是静态 Parser无法并发解析,必须保证多个解析之间串行执行。且错误恢复困难。
因此在实际使用过程中:
- 将static设置为 false(推荐)。
- 也可以给静态 Parser 加上线程安全的 Wrapper
1 | public class ThreadSafeParser { |
生成的 Parser 文件
javacc 会基于语法文件生成 7 个文件。
1 | . |
- TokenMgrError是一个简单的错误类;用于词法分析器检测到的错误 ,是Throwable的子类。
- ParseException是另一个错误类;它用于语法解析器检测到的错误 并且是Exception的子类,因此也是Throwable的子类。
- Token是一个表示令牌的类。每个Token对象都有一个整数字段类型(表示Token的类型)和字符串快照字段(它表示令牌所对应的字符序列)
- SimpleCharStream是一个适配器类,它将字符传递给词法分析器。
- XXXConstants是一个接口,它定义了许多在词法分析器和语法解析器中使用的值。
附录
LookAhead
Parser的工作是读取输入流并确定输入流是否符合语法。产生式的不同定义可能导致不同的耗时结果。以下面为例:
1 | void Input() : |
如果使用abc作为输入字符串,当在 BC 中匹配完成时,由于Input中的 c 无法匹配,所以需要回溯到 BC 中的"b",重新判断是否需要向后 match “c”。
1 | // 解析器必须回溯到开头 |
避免回溯
对于大多数包含解析器的系统来说,这种回溯带来的性能损失是不可接受的。大多数解析器选择在选择点做出决策。
有两种方法可以让你做出正确的决策:
- 修改语法使其更简单。
- 在更复杂的选择点插入提示(Lookahead 规则),以帮助解析器做出正确的选择。
JavaCC语法中的选择点:
|: 分支?: 0次或 1 次*: 0次或 n 次+: 1次或 n 次
选择算法
默认的选择算法在输入流中向前看1个Token,并使用它来帮助在选择点做出选择。例如下面的语法:
1 | void basic_expr() : |
选择确定算法的工作原理如下:
1 | if (next token is <ID>) { |
选择确定算法以从上到下的顺序工作-如果选择了Choice 1,则不考虑其他选择。如果我们需要新增一个新的分支<ID>.<ID>。
1 | void basic_expr() : |
当下一个输入Token是<ID>时,默认算法将始终选择 Choice1。并且从不选择 Choice 4,即使<ID>之后的标记是.。如果输入是id1.id2时,解析器会抛出一个异常:it encountered a . when it was expecting a (.
注意,当构建 Parser时,JavaCC对于这类情况会有 Warning 提示。
1 | Warning: Choice conflict involving two expansions at |
对于下面的语法也存在类似的问题:
1 | void identifier_list() : |
当默认算法在( "," <ID> )*处做出选择时,如果下一个令牌是,,则它将始终进入(...)*构造, 即使,后面的 token 是<INT>。
直觉上,在这种情况下正确的做法是跳过
(...)*结构并返回到funny_list。
在大多数情况下,默认算法工作正常。在它不能正常工作的情况下,JavaCC会向您提供如上所示的警告消息。如果你有一个语法在JavaCC中没有产生任何警告,那么这个语法就是LL(1)语法。
当收到警告消息时,可以用下面方式之一解决。
- 语法修改,通过修改语法使其成为
LL(1)。
1 | void basic_expr() : |
- 可以为生成的解析器提供一些提示(LookAhead 设置)
选择Option 1的唯一好处是它使你的语法表现得更好。JavaCC生成的解析器处理LL(1)构造的速度比其他构造快得多。然而,选择Option 2的好处是你有一个更简单的语法–一个更容易开发和维护的语法,并且专注于人类友好而不是机器友好。
有时Option 2是唯一的选择-特别是在用户操作存在的情况下。
1 | void basic_expr() : |
参考
- [1] JavaCC语法
- [2] JavaCC.LookAhead